Swift 进阶【四】结构体和类
结构体和类的主要不同点:
结构体 (和枚举) 是值类型,而类是引用类型。在设计结构体时,我们可以要求编译器保证不可变性。而对于类来说,我们就得自己来确保这件事情。
内存的管理方式有所不同。结构体可以被直接持有及访问,但是类的实例只能通过引用来间接地访问。结构体不会被引用,但是会被复制。也就是说,结构体的持有者是唯一的,但是类却能有很多个持有者。
使用类,我们可以通过继承来共享代码。而结构体 (以及枚举) 是不能被继承的。想要在不同的结构体或者枚举之间共享代码,我们需要使用不同的技术,比如像是组合、泛型以及协议扩展等。
值类型
值语义 (value semantics)
* 结构体只有一个持有者。比如,当我们将结构体变量传递给一个函数时,函数将接收到结构体的复制,它也只能改变它自己的这份复制。这叫做值语义 (value semantics),有时候也被叫做复制语义。
引用语义 (reference semantics)
* 对于对象来说,它们是通过传递引用来工作的,因此类对象会拥有很多持有者,这被叫做引用语义 (reference semantics)。
因为结构体只有一个持有者,所以它不可能造成引用循环。而对于类和函数这样的引用类型,我们需要特别小心,避免造成引用循环的问题。
编译器所做的对于值类型的复制优化和值语义类型的写时复制行为并不是一回事儿。写时复制必须由开发者来实现,想要实现写时复制,你需要检测所包含的类是否有共享的引用。和自动移除不必要的值类型复制不同,写时复制是需要自己实现的。不过编译器会移除那些不必要的“无效”浅复制,以及像是数组这样的类型中的代码会执行“智能的”写时复制,两者互为补充,都是对值类型的优化。
如果你的结构体只由其他结构体组成,那编译器可以确保不可变性。同样地,当使用结构体时,编译器也可以生成非常快的代码。举个例子,对一个只含有结构体的数组进行操作的效率,通常要比对一个含有对象的数组进行操作的效率高得多。这是因为结构体通常要更直接:值是直接存储在数组的内存中的。而对象的数组中包含的只是对象的引用。最后,在很多情况下,编译器可以将结构体放到栈上,而不用放在堆里。
可变性
Swift 可以让我们在写出安全代码的同时,保留直观的可变代码的风格。
可变性带来的问题,在Foundation中有两个类,NSArray 和NSMutableArray。我们可以用 NSMutableArray 写出下面这样 (会崩溃) 的程序:
1 | let mutableArray: NSMutableArray = [1,2,3] |
当迭代一个 NSMutableArray,你不能去改变它,因为迭代器是基于原始的数组工作的,改变数组将会破坏迭代器的内部状态。
在Swift数组中:
1 | var ary = [1, 2, 3, 4, 5] |
这个例子不会崩溃,这是因为迭代器持有了数组的一个本地的,独立的复制。这样,无论如何移除 ary 中的数据,数组的迭代器的复制依然持有最开始的三个元素。
结构体
对于结构体,Swift 会自动按照成员变量为它添加初始化方法。
1 | struct Point { |
对于上面的方法,可以这样初始化:
1 | let newPoint = Point(x: 0.1, y: 0.2) |
为 Point 重载加号:
1 | func +(lhs: Point, rhs: Point) -> Point { |
这样,我们就可以进行 Point 之间相加了。这里是生成新的一个值,如果是 += 该如何实现呢,这就要用到 inout 关键字。
1 | func +=(lhs: inout Point, rhs: Point) { |
这里接受一个 Point 值,并且在本地改变它的值,然后将新的值复制回去(覆盖原来的 lhs 的值)。这个行为和 mutating 方法如出一辙。实际上,mutating 标记的方法也就是结构体上的普通方法,只不过隐式的 self 被标记为了 inout 而已。
结构体并不意味着你的代码就可以像魔法一般做到线程安全。在闭包内的 while 循环和闭包外的 while 循环都引用了同一个结构体变量,两者会在同时发生改变。
写时复制
在 Swift 标准库中,像是 Array,Dictionary 和 Set 这样的集合类型是通过一种叫做写时复制 (copy-on-write) 的技术实现的。我们这里有一个整数数组:
1 | var x = [1,2,3] |
如果我们创建了一个新的变量 y,并且把 x 赋值给它时,会发生复制,现在 x 和 y 含有的事独立的结构体。在内部,这些 Array 结构体含有指向某个内存的引用。这个内存就是数组中元素所存储的位置,它们位于堆 (heap) 上。在这个时候,两个数组的引用指向的是内存中同一个位置,这两个数组共享了它们的存储部分。不过,当我们改变 x 的时候,这个共享会被检测到,内存将会被复制。这样一来,我们得以独立地改变两个变量。昂贵的元素复制操作只在必要的时候发生,也就是我们改变这两个变量的时候发生复制:
1 | x.append(5) |
如果 Array 结构体中的引用在数组被改变的一瞬间时是唯一的话 (比如,没有声明 y),那么也不会有复制发生,内存的改变将在原地进行。这种行为就是写时复制,作为一个结构体的作者,你并不能免费获得这种特性,你需要自己进行实现。当你自己的类型内部含有一个或多个可变引用,同时你想要保持值语义,并且避免不必要的复制时,为你的类型实现写时复制是有意义的。
闭包和可变性
例如,有一个函数在每次被调用时生成一个唯一的整数,直到 Int.max。这可以通过将状态移动到函数外部来实现。换句话说,这个函数对变量 i 进行了闭合 (close)。
1 | var i = 0 |
封装成闭包
1 | func uniqueIntegerProvider() -> () -> Int { |
函数也是引用类型,如果我们将函数A赋值给另一个变量,编译器不会复制这个函数或者 i。相反,它将会创建一个指向相同函数的引用。
这对所有的闭包和函数来说都是正确的:如果我们传递这些闭包和函数,它们会以引用的方式存在,并共享同样的状态。
Swift 的结构体一般被存储在栈上,而非堆上。不过这其实是一种优化:默认情况下结构体是存储在堆上的,但是在绝大多数时候,这个优化会生效,并将结构体存储到栈上。当结构体变量被一个函数闭合的时候,优化将不再生效,此时这个结构体将存储在堆上。因为变量 i 被函数闭合了,所以结构体将存在于堆上。这样一来,就算uniqueIntegerProvider 退出了作用域,i 也将继续存在。与此相似,如果结构体太大,它也会被存储在堆上。
内存
当把 Swift 和使用垃圾回收机制的语言进行对比时,第一印象是它们在内存管理上似乎很相似。大多数时候,你都不太需要考虑它。不过,看看下面的例子:
1 | var window: Window? = Window() |
首先,我们创建了 window 对象,window 的引用计数将为 1。之后创建 view 对象时,它持有了 window 对象的强引用,所以这时候 window 的引用计数为 2,view 的计数为 1。接下来,将 view 设置为 window 的 rootView 将会使 view 的引用计数加一。此时 view 和 window 的引用计数都是 2。当把两个变量都设置为 nil 后,它们的引用计数都会是 1。即使它们已经不能通过变量进行访问了,但是它们却互相有着对彼此的强引用。这就被叫做引用循环,当处理类似于这样的数据结构时,我们需要特别小心这一点。因为存在引用循环,这样的两个对象在程序的生命周期中将永远无法被释放。
weak 引用
要打破引用循环,我们需要确保其中一个引用要么是 weak,要么是 unowned。weak 引用表示不增加引用计数,并且当被引用的对象被释放时,将该 weak 引用自身设置为 nil。
构造函数
* 构造函数 ,是一种特殊的方法。主要用来在创建对象时初始化对象, 即为对象成员变量赋初始值,总与new运算符一起使用在创建对象的语句中。特别的一个类可以有多个构造函数 ,可根据其参数个数的不同或参数类型的不同来区分它们 即构造函数的重载。
析构函数
* 析构函数(destructor) 与构造函数相反,当对象结束其生命周期时(例如对象所在的函数已调用完毕),系统自动执行析构函数。析构函数往往用来做“清理善后” 的工作(例如在建立对象时用new开辟了一片内存空间,delete会自动调用析构函数后释放内存)。
unowned 引用
因为 weak 引用的变量可以变为 nil,所以它们必须是可选值类型,但是有些时候这并不是你想要的。例如,也许我们知道我们的 view 将一定有一个 window,这样这个属性就不应该是可选值,而同时我们又不想一个 view 强引用 window。这种情况下,我们可以使用 unowned 关键字,这将不持有引用的对象,但是却假定该引用会一直有效。
对每个 unowned 的引用,Swift 运行时将为这个对象维护另外一个引用计数。当所有的 strong 引用消失时,对象将把它的资源 (比如对其他对象的引用) 释放掉。不过,这个对象本身的内存将继续存在,直到所有的 unowned 引用也都消失。这部分内存将被标记为无效 (有时候我们也把它叫做僵尸 (zombie) 内存),当我们试图访问这样的 unowned 引用时,就会发生运行时错误。
当你不需要 weak 的时候,还是建议使用 unowned。一个 weak 变量总是需要被定义为 var,而 unowned 变量可以使用 let 来定义。不过,只有在你确定你的引用将一直有效时,才应该使用 unowned。
个人来说,我经常发现自己即使是在那些可以用 unowned 的场合,也还一直在用 weak。我们可能会时不时地对一些代码进行重构,而这可能会导致我们之前对于对象有效的假设失效,这种情况下使用 unowned 就很危险。当使用 weak 时,一个好处是编译器强制我们需要处理引用为 nil 时的可能性。
结构体和类使用实践
例子:银行账户转账功能:
基于类的实现:
1 | // 银行账户 |
缺点:
* 不是线程安全的
基于纯结构体的实现:
1 | struct Account { |
优点:
* 线程安全
缺点:
* 程序变得啰嗦
基于 inout 结构体实现
1 | func transfer |
当我们调用含有 inout 修饰的参数的函数时,我们需要为变量加上 & 符号。不过注意,和传递 C 指针的语法不同,这里不代表引用传递。当函数返回的时候,被改变的值会被复制回调用者中去:
1 | var alice = Account(funds: 100) |
优点:
* 线程安全,保证了函数体内的稳定性
* 写起来和基于类的策略一样容易
闭包和内存
在 Swift 中,除了类以外,函数 (包括闭包) 也是引用类型。我们在闭包和可变性的部分已经看到过,闭包可以捕获变量。如果这些变量是引用类型的话,闭包将持有对它们的强引用。
引用循环:
对象 A 引用了对象 B,但是对象 B 引用了一个包含对象 A 的回调。让我们考虑之前的例子,当一个视图引用了它的窗口时,窗口通过一个弱引用指向这个根视图。在此基础上,窗口现在多了一个 onRotate 回调,它是一个可选值,初始值为 nil:
1 | class View { |
如果我们像之前那样创建视图,设置窗口,一切照旧,我们不会引入引用循环:
1 | var window: Window? = Window() |
视图强引用了窗口,但是窗口只是弱引用视图,一切安好。但是,如果我们对 onRotate 回调进行配置,并在其中使用 view 的话,我们就会引入一个引用循环:
1 | window?.onRotate = { |
视图引用了窗口,窗口引用回调,回调引用视图:循环形成。
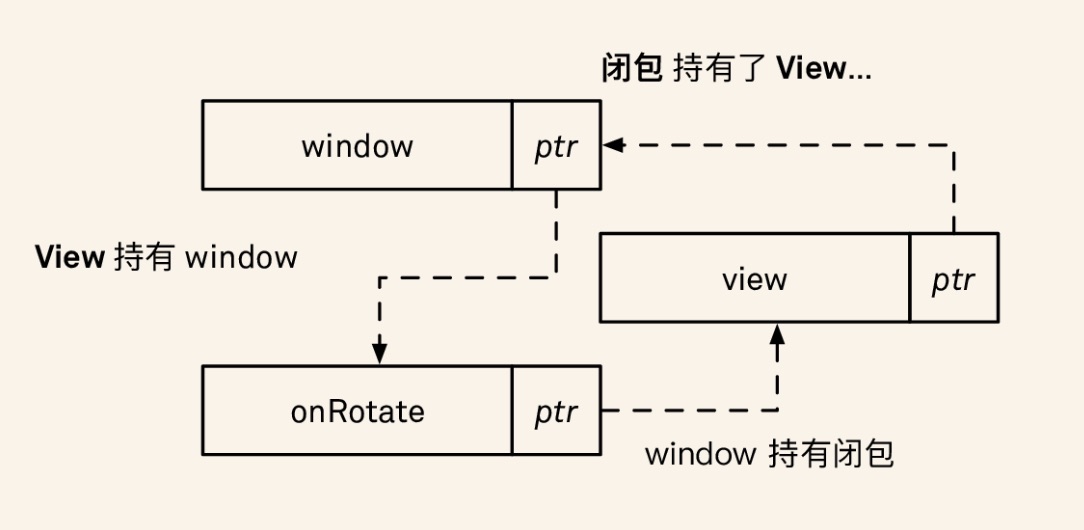
我们需要找到一种办法来打破这个引用循环。有三种方式可以打破循环,每种方式都在图表中用箭头表示出来了:
- 我们可以让指向 Window 的引用变为 weak。不过不幸的是,这会导致 Window 消失,因为没有其他指向它的强引用了。
- 我们可以将 Window 的 onRotate 闭包声明为 weak。不过这也不可行,因为闭包其实是没有办法被标记为 weak 的,而且就算 weak 闭包是可能的,所有的 Window 的用户需要知道这件事情,因为有时候会需要手动引用这个闭包。
- 我们可以通过使用捕获列表 (capture list) 来让闭包不去引用视图。这在上面这些例子中是唯一正确的选项。
捕获列表:
为了打破上面的循环,我们需要保证闭包不去引用 视图。我们可以通过使用捕获列表并将捕获变量 view 标记为 weak 或者 unowned 来达到这个目的。
1 | window?.onRotate = { [weak view] in |
捕获列表也可以用来初始化新的变量。比如,如果我们想要用一个 weak 变量来引用窗口,我们可以将它在捕获列表中进行初始化,我们甚至可以定义完全不相关的变量,就像这样:
1 | window?.onRotate = { [weak view, weak myWindow=window, x=5*5] in |
这和上面闭包的定义几乎是一样的,只有在捕获列表的地方有所不同。这些变量的作用域只在闭包内部,在闭包外面它们是不能使用的。