8 Mistakes to Avoid while Using RxSwift
Judging by the number of talks, articles and discussions related to reactive programming in Swift, it looks like the community has been taken by the storm. It’s not that the concept of reactiveness itself is a new shiny thing. The idea of using it for the development within the Apple ecosystem had been played with for a long time. Frameworks like ReactiveCocoa have existed for years and did an awesome job at bringing the reactive programming to the Objective-C. However, the new and exciting features of Swift make it even more convenient to go full in on the “signals as your apps’ building blocks” model.
Here at Polidea, we’ve also embraced the reactive paradigm, mostly in the form of RxSwift, the port of C#-originated Reactive Extensions. And we couldn’t be happier! It helps us build more expressive and better-architectured apps faster and easier. Unifying various patterns (target-action, completion block, notification) under a universal API that is easy to use, easy to compose and easy to test has so many benefits. Also, introducing new team members is way easier now, when so much logic is written with methods familiar either from sequences (map, filter, zip, flatMap) or from other languages that Reactive Extensions had been ported to.
The process of learning RxSwift, however, hasn’t been painless. We’ve made many mistakes, fallen into many traps and eventually arrived at the other end to share what we’ve learned along the way. This is what this series is about: showing you the most common pitfalls to avoid when going reactive. They all come from the everyday practical use of RxSwift in non-trivial applications. It took us many hours to learn our lessons and we hope that with our help it’s going to take you only few minutes to enjoy the benefits of reactive programming without ever encountering its dark side.
So, let’s start!
Not disposing a subscription
When you started using RxSwift for the first time, you’ve probably tried to observe some events by writing:
1 | observable |
Such an expression was, however, openly criticized by Xcode with the default Result to call to 'subscribe' is unused warning. Luckily, there’s an easy fix available just around the corner. Telling the compiler that we ignore the call result with _ = would be enough, right? So now it’s:
1 | _ = observable |
and everything is fixed, isn’t it? If you think so, prepare yourself for a treat. There’re probably a whole lot of low-hanging fruits of undisposed subscriptions just waiting to be picked from your memory-management tree. Ignoring the subscription’s result is a clear path to memory leaks. While there are situations in which you’ll be spared any problems, in the worst-case scenario both your observable and the observer closure will never be released. The bad news is that by ignoring the value returned from subscribe method you’re giving away the control over which scenario is going to happen.
To understand the problem, I’ll show you the mental model of the subscription process in terms of memory-management first. Then, I’ll derive the best practices. Finally, I’m going to peek into RxSwift source code to understand what is actually happening in the current (v3.X/4.0) implementation and how it relates to the mental model presented earlier.
The mental model for subscription memory-management
Calling subscribe creates a reference cycle that retains both the observable and the observer. Neither of them is going to be released unless the cycle is broken, and it’s broken only in two situations:
- when the observable sequence completes, either with
.completedor.errorevent, - when someone explicitly calls
.dispose()on the reference cycle manager returned bysubscribemethod.
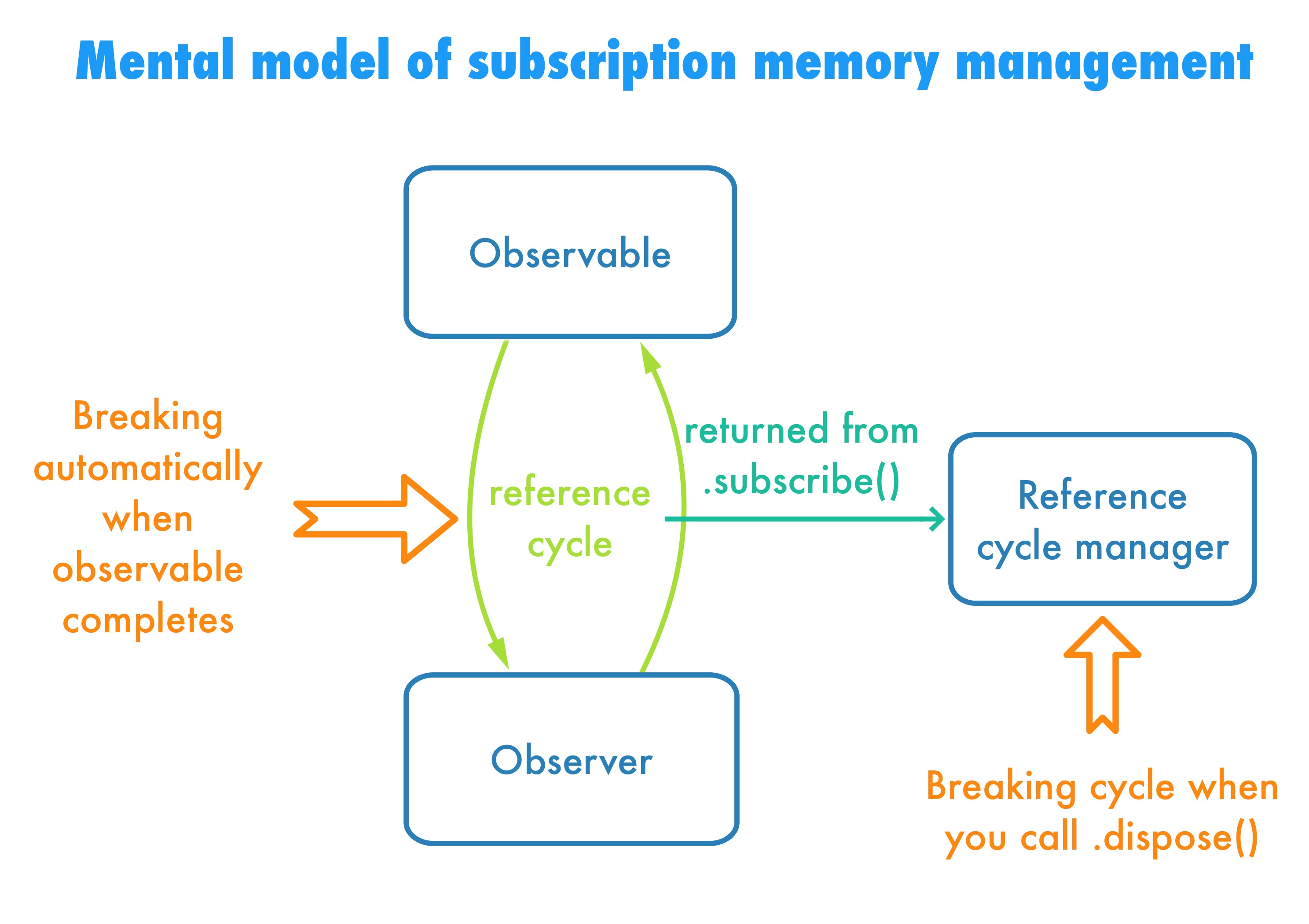
The details may vary, but the basic idea of what it means to subscribe holds regardless of your particular observable, observer or subscription. The crucial thing to spot is that ignoring the reference cycle manager, aka disposable, strips you of the possibility to break reference cycle yourself. It is your gateway drug into the memory arrangement, and once it’s not available, there is no going back. If you use the _ = syntax, you basically state that the only way for the observable and observer to be released is by completing the observable sequence.
This might sometimes be exactly what you want! For example, if you’re calling Observable.just, it doesn’t really matter that you won’t ensure breaking the cycle. The single element is being emitted instantaneously, followed by .completed event. There are, however, many situations in which you might not be entirely sure of the completion possibilities for observable in question:
- you’re given the
Observablefrom another object and the documentation doesn’t state whether it completes, - you’re given the
Observablefrom another object and the documentation does state it completes, but there have been some changes in the internal implementation of that object along the way and no one remembered to update documentation, - the
Observableis explicitly not completing (examples includeVariable,Observable.interval, subjects), - there is an error in observable implementation, such as forgetting to send
.completedevent inObservable.createclosure.
Since you’re rarely in control of all the observables in your app, and even then there’s a possibility for a mistake, the rule of thumb is to ensure yourself that the reference cycle will be broken. Either keep the reference todisposableand call the.dispose()method when the time comes, or use a handy helper likeDisposeBagthat’s gonna do it for you. You might also provide a separate cycle-breaking observable with.takeUntiloperator. What way to choose depends on your particular situation, but always remember that:
Subscription creates a reference cycle between the observable and the observer. It might be broken implicitly, when observable completes, or explicitly, via
.dispose()call. If you’re not 100% sure when or whether observable will complete, break the subscription reference cycle yourself!
Now that we’ve cleared things up, I feel like I owe you a little bit of explanation. The mental model I’ve drawn above is, well, a mental model, and therefore not strictly correct. What’s happening in the current RxSwift implementation (version 3.x/4.x at the time of writing) is a little bit more complicated. To understand the actual behavior, let us have a deeper dive into the RxSwift internals.
The implementation of the subscribe method
Where is the subscribe method implemented? First place to search would be, unsurprisingly, the ObservableType.swift file. It contains declaration of subscribe method as a part of the ObservableType protocol:
1 | // ObservableType.swift |
What implements this protocol? Basically, all the various types of observables. Let’s concentrate on the major implementation called Observable, since it’s a base class for all but one of the observables defined in RxSwift. Its version of subscribe method is short and simple:
1 | // Observable.swift |
Oh, the abstract method. We need to look into the Observable subclasses then. A quick search reveals that there are 14 different overridden subscribe methods within the RxSwift source code at the time of writing. We can put each of them in one of three buckets:
- implementations in subjects, which provide their own subscription logic due to the extraordinary place they occupy in the RxSwift lore,
- implementations in connectable observables, which must deal with subscriptions in a special way due to their ability of multicasting,
- implementation in Producer, a subclass of
Observablewhich provides the subscription logic for most of the operators you’ve grown to love and use.
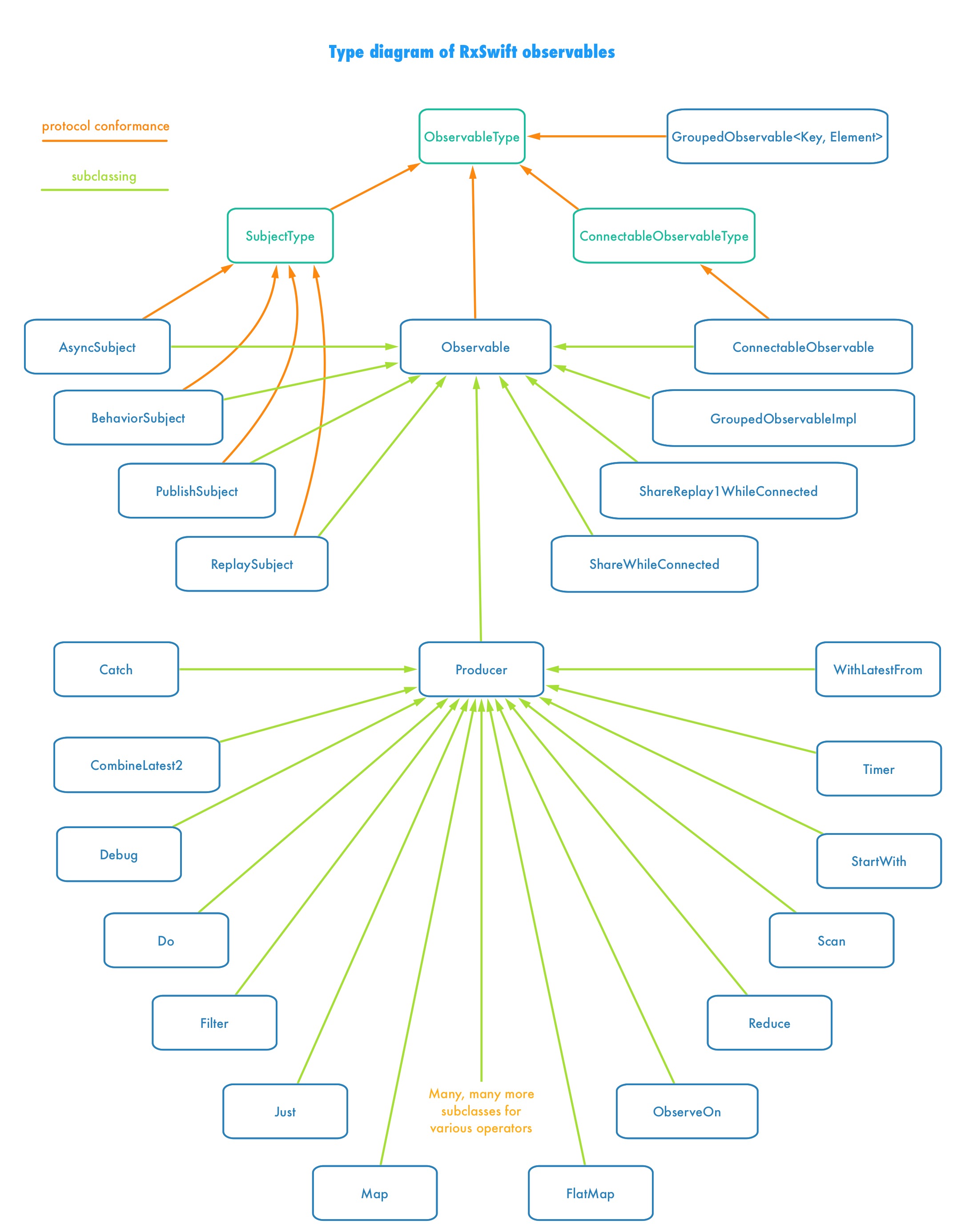
Let’s concentrate on Producer type, since it represents the variant of observable that is simplest to reason about: the emitter of the sequence of events, from the single source to single recipient. It’s definitely the most common use case. Almost all the operators are derived from Producer base class. While a few of them provide a dedicated subscription logic that’s optimized further to their particular needs (see Just, Empty or Error for basic examples), the vast majority use the following implementation of subscribe from Producer (some scheduler-related logic was stripped for better readability):
1 | // Producer.swift |
So, what’s happening here? First, the observable creates a SinkDisposer object. Then it uses the SinkDisposer instance to create two additional objects: sink and subscription. They both have the same type: Disposable, which is a protocol exposing a single dispose method. These two objects are being passed back to SinkDisposer via a setter method, which suggests, correctly, that their references will be kept. After all that setup is done, the SinkDisposer is being returned. So, when we’re calling .dispose() on the object returned from the subscribe method to break the subscription, we’re actually calling it on SinkDisposer instance.
So far, so good. One mystery down, still a few to go. Let’s dive into two crucial steps performed here: let sinkAndSubscription = run(observer, cancel: disposer) and disposer.setSinkAndSubscription(sink: sinkAndSubscription.sink, subscription: sinkAndSubscription.subscription) methods. They are, as you’ll see, the essential parts of creating the reference cycle that keeps the subscription alive.
Sinking in the sea of Observables
The run method is provided by the Producer, but only in an abstract variant:
1 | // Producer.swift |
The actual logic is specific to the particular Producer subclass. Before we check them, it’s crucial to understand the pattern that is very common across the RxSwift operators implementation: sink. This is the way that RxSwift deals with the complexity of observable streams and how it separates the creation of the observable from the logic that is being run the moment you subscribe to it.
The idea is simple: when you use the particular operator (say you map the existing observable), it returns an instance of a particular observable type dedicated to the task at hand. So calling Observable.just(1) gives you back the instance of Just class, which is a subclass of the Producer optimized for returning just one element and then completing. When you call Observable<Int>.just(1).map { $0 == 42 }, you’re being given back the instance of Map class, which is a subclass of the Producer optimized for applying the closure to each element in the .next event. However, at the very moment you create an observable, there’s nothing being actually sent to anyone yet, because no one has subscribed. The actual work of passing the events starts during the subscribe method, more precisely: in the run method that we’re so interested in.
That’s where the sink pattern shines. Each observable type has its own dedicated Sink subclass. For the interval operator, represented by the Timer observable, there is the TimerSink. For the flatMap operator, represented by the FlatMap observable, there is the FlatMapSink. For the catchErrorJustReturn operator, represented by the Catch observable, there is the CatchSink. I think you get the idea!
But what is this Sink object, exactly? It is the place that stores the actual operator logic. So, for the interval, the TimerSink is the place that schedules sending events after each period and keeps track of the internal state (i.e. how many events were already sent). For the flatMap, the FlatMapSink (and its superclass, MergeSink ) is the place that subscribes to the observables returned from flatmapping closure, keeps track of them and passes their events further. You may basically think of a Sink as a wrapper for the observer. It listens for the events from observable, applies the operator-related logic and then passes those transformed events further down the stream.
This is how RxSwift isolates the creation of observables from the execution of subscription logic for Producer -based observables. The former is encapsulated in the Observable subclass, the latter is provided by the Sink subclass. The separation of responsibilities greatly simplifies the actual objects’ implementations and makes it possible to write multiple variants of Sink optimized for different scenarios.
Sink full of knowledge
Now that we know what the sink pattern is, let’s go back to the run method. Each of these Producer subclasses provides its own run implementation. While details may vary, it usually can be abstracted into three steps:
- create a
sinkobject as an instance of a class that derives fromSinktype, - create a subscription instance, usually by running
sink.runmethod, - return both instances wrapped in a tuple.
To clarify things further, please look at the FlatMap.run example:
1 | // Merge.swift, FlatMap observable class |
The most important thing from the memory-management perspective is that in the moment of subscription the sink is given everything that’s needed to do the job:
- the events source (aka Observable ),
- the event recipient (called
observer), - the operator-related data (for example, the flatmapping closure),
- and the
SinkDisposerinstance (under the namecancel).sinkis free to store as many of these references as it sees fit for providing the required behavior of the operator. At the minimum, it’s gonna store theobserverand, what’s gonna be crucial later, theSinkDisposer. Possibly more! Looking at the memory graph,sinkquickly becomes the Northern Star in the constellation of objects related to the subscription.
There is, however, one more object returned from observable’s run method. It’s subscription. This is the object that takes care of the logic that should be run when the subscription is being disposed of. Remember create operator? It takes a closure that returns Disposable, an object responsible for performing the cleanup. This is the same Disposable that’s returned from AnonymousObservableSink‘s run method as subscription. For each operator there might be some tasks to cancel, some resources to free, some internal subscription to dispose of. They’re all enclosed in the subscription object, and the ability to perform the cleanup is exposed via subscription.dispose method.
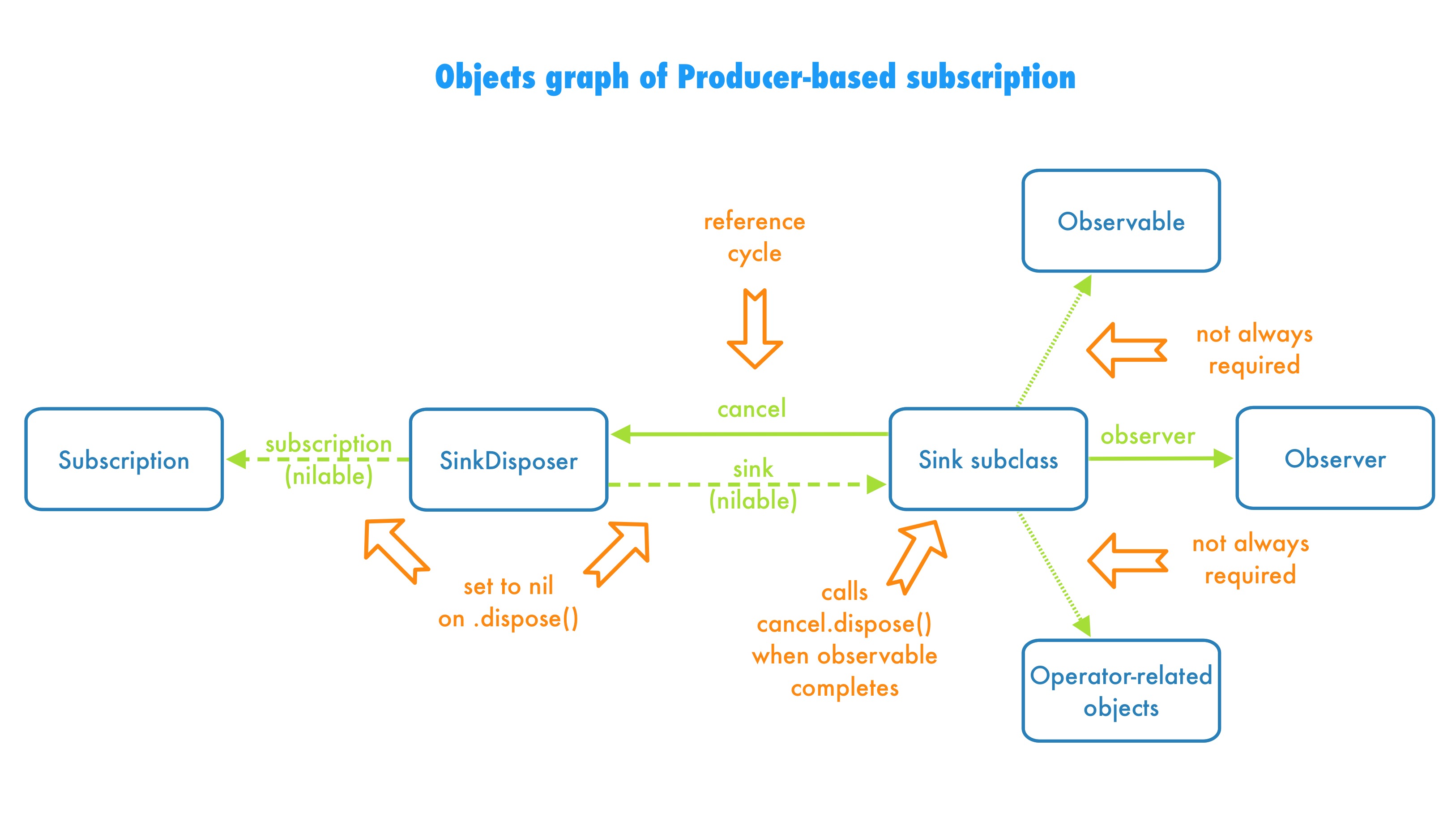
The Producer‘s reference cycle: Sink and SinkDisposer
Knowing that, let’s get back to the last component of the subscribe method implementation. Before the SinkDisposer is returned, the setSinkAndSubscription method is called. It does exactly what you might expect: the sink and subscription objects are passed via setter and kept in the SinkDisposer properties. They are referenced strongly, but wrapped into Optionals, which makes it possible set the references to nil later.
Have you already spotted the reference cycle from our mental model? It’s hidden in the plain sight! sink stores the reference to SinkDisposer, and SinkDisposer stores the reference to sink. That’s why the subscription doesn’t release itself on the scope exit. Two objects keep each other alive, in an eternal hug of memory-lockup, until the end of the app. And since sink keeps SinkDisposer as non-Optional property, the one and only way of breaking the cycle is by asking the SinkDisposer to set the sink Optional reference to nil. And guess what? This is exactly what’s happening in the SinkDisposer.dispose method. It calls dispose on sink, then it calls dispose on subscription and then it nils out references to break the retain cycle. So for the Producer -based observables, the SinkDisposer is the reference cycle manager from the mental model that we’ve introduced earlier.
After all those details, you might wonder how come the reference cycle breaks itself when observable completes? Well, we’ve just stated that it requires SinkDisposer.dispose() method, so the answer is simple. The central point of subscription process, sink object, keeps the reference to SinkDisposer and also receives all the events from the observable. So once it gets either .completed or .error event and once its own logic determines that this is the sequence completion, it simply calls dispose method on its SinkDisposer reference. This way the cycle is being broken from the inside.
To summarize the process, here comes the diagram of the actual reference cycle in the usual Producer -based observable subscription:
The road goes ever on and on
Aren’t you curious what happens in non- Producer -based cases, such as subjects or connectable observables? The concept is very similar. There is always a reference cycle that’s controlled by some kind of reference cycle manager and there is always a way of breaking this cycle by dispose method invocation. I encourage you to dive into RxSwift source code and see for yourself!
Now it is clear where the mental model comes from. The details of particular subscription vary, and each observable type has specific optimizations applied for better performance and cleaner architecture. However, the basic idea prevails: there’s a reference cycle and the only way of breaking this cycle is either by completing the observable or through reference cycle manager.
Relying on the completion of the observable, while useful in many real-life situations, should always be a road taken with much care and deliberation. If you’re not sure of how to handle the subscription’s memory management, or you simply want your code to be more resilient to the future changes, it’s always best to default to supplying a mechanism of breaking the reference cycle explicitly.
That’s all for this time. More ways to shoot yourself in the foot with RxSwift are coming. Next time we’re going to look at memory management from a different perspective, focusing not on the subscription process, but on what’s being passed to operators. Until then, don’t forget to follow Polidea on Twitter for more mobile development related posts!
8 Mistakes to Avoid while Using RxSwift. Part 1 - Polidea