C 语言重拾【五】指针
指针简介
指针?什么是指针?从根本上看,指针(pointer)是一个值为内存地址的变量(或数据对象)。正如char类型变量的值是字符,int类型变量的值是整数,指针变量的值是地址。在 C 语言中,指针有许多用法。本章将介绍如何把指针作为函数参数使用,以及为何要这样用。
假设一个指针变量名是ptr,可以编写如下语句:
1 | ptr = &pooh; // 把 pooh 的地址赋给 ptr |
对于这条语句,我们说ptr“指向”pooh。ptr和&pooh的区别是ptr是变量,而&pooh是常量。或者,ptr是可修改的左值,而&pooh是右值。还可以把ptr指向别处:
1 | ptr = &bah; // 把 ptr 指向 bah,而不是 pooh |
现在ptr的值是bah的地址。
要创建指针变量,先要声明指针变量的类型。假设想把ptr声明为储存int类型变量地址的指针,就要使用下面介绍的新运算符。
间接运算符:*
假设已知ptr指向bah,如下所示:
1 | ptr = &bah; |
然后使用间接运算符*(indirection operator)找出储存在bah中的值,该运算符有时也称为解引用运算符(dereferencing operator)。不要把间接运算符和二元乘法运算符(*)混淆,虽然它们使用的符号相同,但语法功能不同。
1 | val = *ptr; // 找出 ptr 指向的值 |
语句ptr = &bah;和val = *ptr;放在一起相当于下面的语句:
1 | val = bah; |
由此可见,使用地址和间接运算符可以间接完成上面这条语句的功能,这也是“间接运算符”名称的由来。
小结:与指针相关的运算符
地址运算符:&
一般注解:
后跟一个变量名时,&给出该变量的地址。
示例:&nurse表示变量nurse的地址。
地址运算符:*
一般注解:
后跟一个指针名或地址时,*给出储存在指针指向地址上的值。
示例:
2
3
ptr = &nurse; // 指向 nurse 的指针
val = *ptr; // 把 ptr 指向的地址上的值赋给 val执行以上 3 条语句的最终结果是把 22 赋给
val。
声明指针
相信读者已经很熟悉如何声明int类型和其他基本类型的变量,那么如何声明指针变量?你也许认为是这样声明:
1 | pointer ptr; // 不能这样声明指针 |
为什么不能这样声明?因为声明指针变量时必须指定指针所指向变量的类型,因为不同的变量类型占用不同的存储空间,一些指针操作要求知道操作对象的大小。另外,程序必须知道储存在指定地址上的数据类型。long和float可能占用相同的存储空间,但是它们储存数字却大相径庭。下面是一些指针的声明示例:
1 | int * pi; // pi 是指向 int 类型变量的指针 |
类型说明符表明了指针所指向对象的类型,星号(*)表明声明的变量是一个指针。int * pi;声明的意思是pi是一个指针,*pi是int类型(见图9.5)。
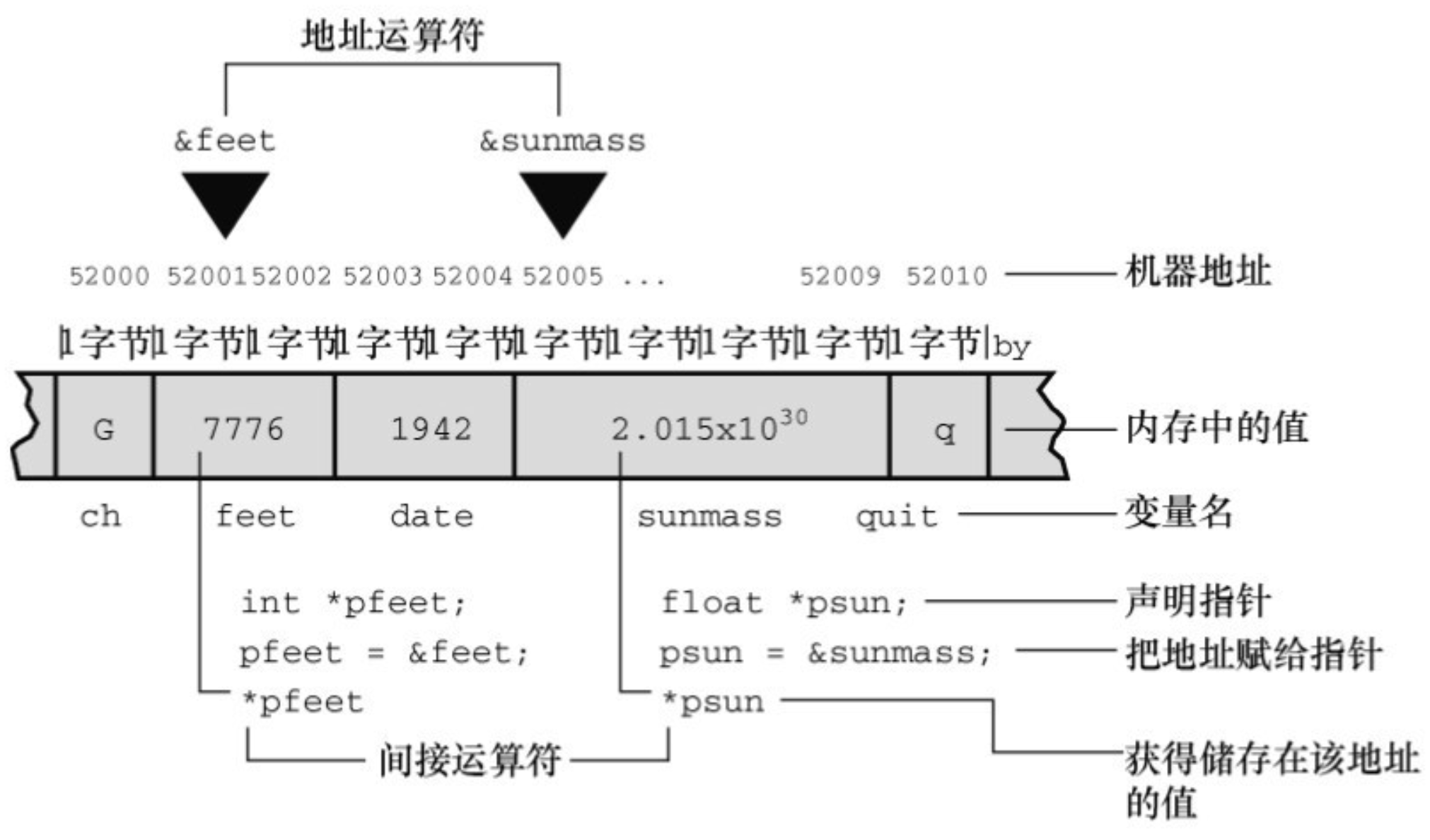
*和指针名之间的空格可有可无。通常,程序员在声明时使用空格,在解引用变量时省略空格。pc指向的值(*pc)是char类型。pc本身是什么类型?我们描述它的类型是 “指向char类型的指针”。pc的值是一个地址,在大部分系统内部,该地址由一个无符号整数表示。但是,不要把指针认为是整数类型。一些处理整数的操作不能用来处理指针,反之亦然。例如,可以把两个整数相乘,但是不能把两个指针相乘。所以,指针实际上是一个新类型,不是整数类型。因此,如前所述,ANSI C 专门为指针提供了%p格式的转换说明。
使用指针在函数间通信
我们才刚刚接触指针,指针的世界丰富多彩。本节着重介绍如何使用指针解决函数间的通信问题。请看程序清单 9.15,该程序在interchange()函数中使用了指针参数。稍后我们将对该程序做详细分析。
程序清单 9.15 swap3.c 程序
1 | /* swap3.c -- 使用指针解决交换函数的问题 */ |
该程序是否能正常运行?下面是程序的输出:
1 | Originally x = 5 and y = 10. |
没问题,一切正常。接下来,我们分析程序清单 9.15 的运行情况。首先看函数调用:
1 | interchange(&x, &y); |
该函数传递的不是x和y的值,而是它们的地址。这意味着出现在interchange()原型和定义中的形式参数u和v将把地址作为它们的值。因此,应把它们声明为指针。由于x和y是整数,所以u和v是指向整数的指针,其声明如下:
1 | void interchange (int * u, int * v) |
接下来,在函数体中声明了一个交换值时必需的临时变量:
1 | int temp; |
通过下面的语句把x的值储存在temp中:
1 | temp = *u; |
记住,u的值是&x,所以u指向x。这意味着用*u即可表示x的值,这正是我们需要的。不要写成这样:
1 | temp = u; /* 不要这样做 */ |
因为这条语句赋给temp的是x的地址(u的值就是x的地址),而不是x的值。函数要交换的是x和y的值,而不是它们的地址。
与此类似,把y的值赋给x,要使用下面的语句:
1 | *u = *v; |
这条语句相当于:
1 | x = y; |
我们总结一下该程序示例做了什么。我们需要一个函数交换x和y的值。把x和y的地址传递给函数,我们让interchange()访问这两个函数。使用指针和*运算符,该函数可以访问储存在这些位置的值并改变它们。
可以省略 ANSI C 风格的函数原型中的形参名,如下所示:
1 | void interchange(int *, int *); |
一般而言,可以把变量相关的两类信息传递给函数。如果这种形式的函数调用,那么传递的是x的值:
1 | function1(x); |
如果下面形式的函数调用,那么传递的是x的地址:
1 | function2(&x); |
第 1 种形式要求函数定义中的形式参数必须是一个与x的类型相同的变量:
1 | int function1(int num) |
第 2 种形式要求函数定义中的形式参数必须是一个指向正确类型的指针:
1 | int function2(int * ptr) |
如果要计算或处理值,那么使用第 1 种形式的函数调用;如果要在被调函数中改变主调函数的变量,则使用第 2 种形式的函数调用。我们用过的scanf()函数就是这样。当程序要把一个值读入变量时(如本例中的num),调用的是scanf("%d", &num)。scanf()读取一个值,然后把该值储存到指定的地址上。
对本例而言,指针让interchange()函数通过自己的局部变量改变main()中变量的值。
熟悉 Pascal 和 Modula-2 的读者应该看出第 1 种形式和 Pascal 的值参数相同,第 2 种形式和 Pascal 的变量参数类似。C++ 程序员可能认为,既然 C 和 C++ 都使用指针变量,那么 C 应该也有引用变量。让他们失望了,C 没有引用变量。对 BASIC 程序员而言,可能很难理解整个程序。如果觉得本节的内容晦涩难懂,请多做一些相关的编程练习,你会发现指针非常简单实用(见图9.6)。
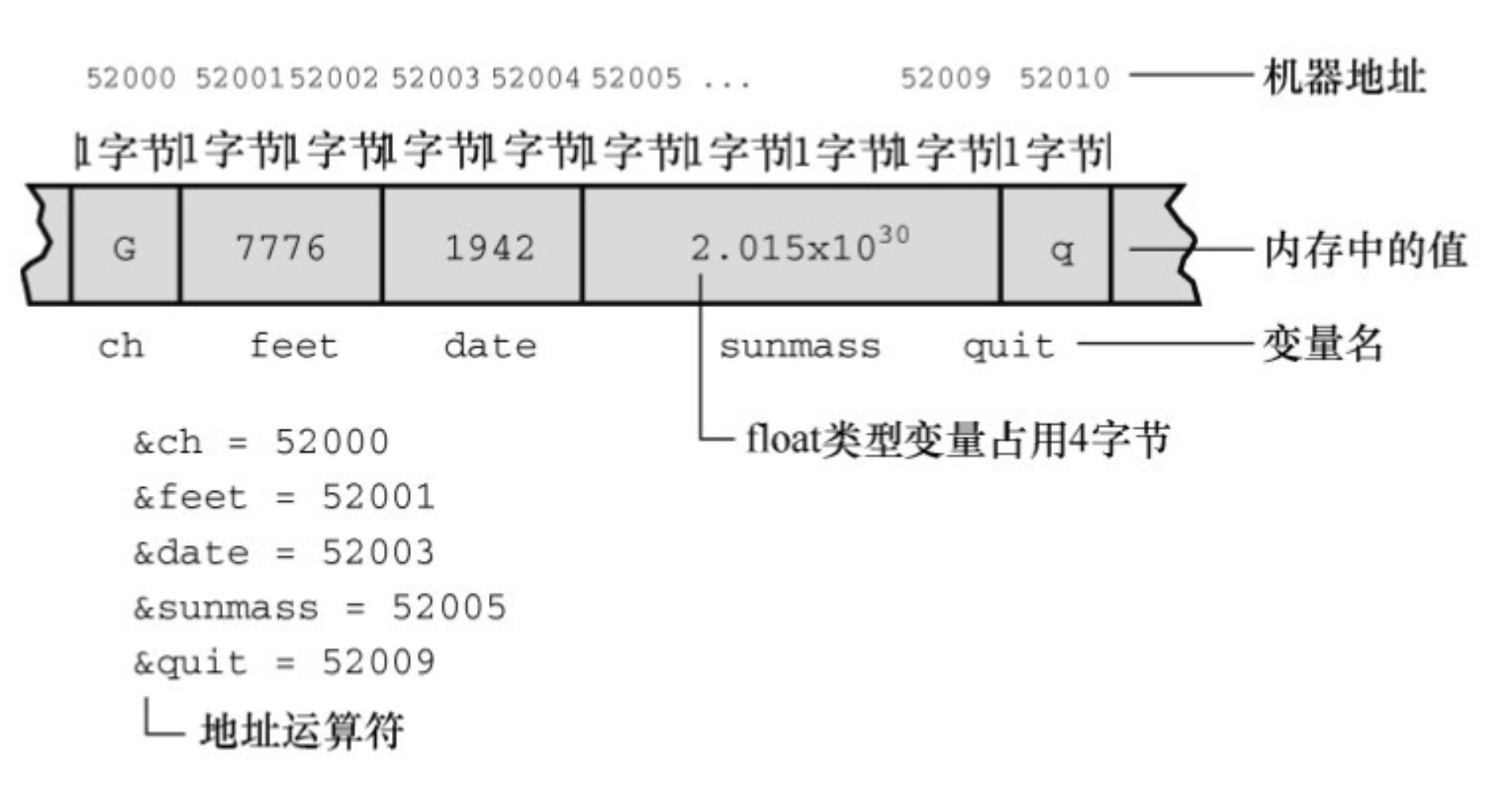
变量:名称、地址和值
通过前面的讨论发现,变量的名称、地址和变量的值之间关系密切。我们来进一步分析。
编写程序时,可以认为变量有两个属性:名称和值(还有其他性质,如类型,暂不讨论)。计算机编译和加载程序后,认为变量也有两个属性:地址和值。地址就是变量在计算机内部的名称。在许多语言中,地址都归计算机管,对程序员隐藏。然而在 C 中,可以通过
&运算符访问地址,通过*运算符获得地址上的值。例如,&barn表示变量barn的地址,使用函数名即可获得变量的数值。例如,printf("%d\n", barn)打印barn的值,使用*运算符即可获得储存在地址上的值。如果pbarn= &barn;,那么*pbarn表示的是储存在&barn地址上的值。简而言之,普通变量把值作为基本量,把地址作为通过
&运算符获得的派生量,而指针变量把地址作为基本量,把值作为通过*运算符获得的派生量。虽然打印地址可以满足读者好奇心,但是这并不是
&运算符的主要用途。更重要的是使用&、*和指针可以操纵地址和地址上的内容,如 swap3.c 程序(程序清单9.15)所示。
指针和数组
指针提供一种以符号形式使用地址的方法。因为计算机的硬件指令非常依赖地址,指针在某种程度上把程序员想要传达的指令以更接近机器的方式表达。因此,使用指针的程序更有效率。尤其是,指针能有效地处理数组。数组表示法其实是在变相地使用指针。
我们举一个变相使用指针的例子:数组名是数组首元素的地址。也就是说,如果flizny是一个数组,下面的语句成立:
1 | flizny == &flizny[0]; // 数组名是该数组首元素的地址 |
flizny和&flizny[0]都表示数组首元素的内存地址(&是地址运算符)。两者都是常量,在程序的运行过程中,不会改变。但是,可以把它们赋值给指针变量,然后可以修改指针变量的值,如程序清单 10.8 所示。注意指针加上一个数时,它的值发生了什么变化(转换说明%p通常以十六进制显示指针的值)。
程序清单 10.8 pnt_add.c 程序
1 | // pnt_add.c -- 指针地址 |
下面是该例的输出示例:
| short | double | |
|---|---|---|
| pointers + 0: | 0x7fff5fbff8dc | 0x7fff5fbff8a0 |
| pointers + 1: | 0x7fff5fbff8de | 0x7fff5fbff8a8 |
| pointers + 2: | 0x7fff5fbff8e0 | 0x7fff5fbff8b0 |
| pointers + 3: | 0x7fff5fbff8e2 | 0x7fff5fbff8b8 |
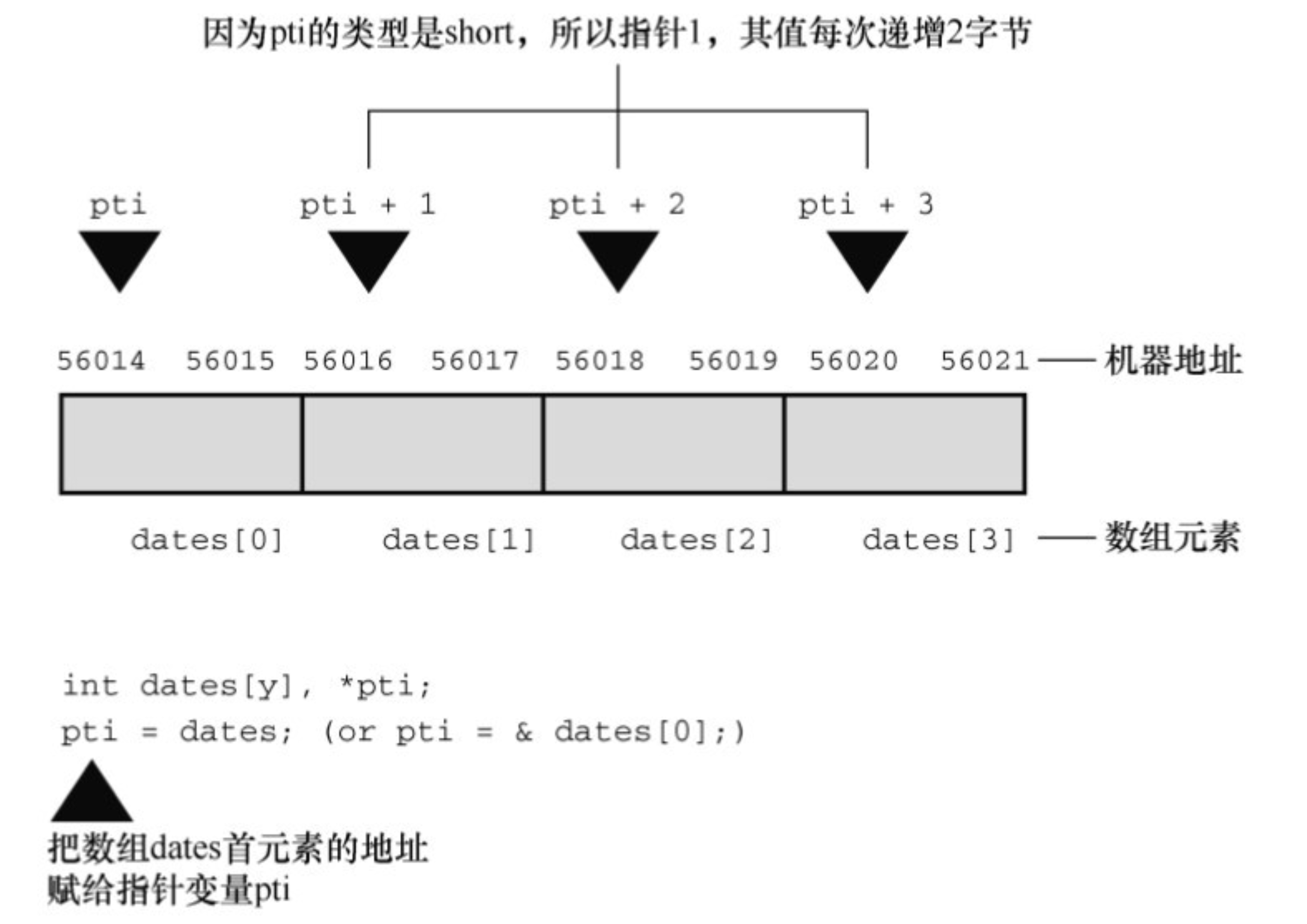
第 2 行打印的是两个数组开始的地址,下一行打印的是指针加 1 后的地址,以此类推。注意,地址是十六进制的,因此dd比dc大1,a1比a0大 1。但是,显示的地址是怎么回事?
0x7fff5fbff8dc + 1 是否是 0x7fff5fbff8de?
0x7fff5fbff8a0 + 1 是否是 0x7fff5fbff8a8?
我们的系统中,地址按字节编址,short类型占用 2 字节,double类型占用 8 字节。在 C 中,指针加 1 指的是增加一个存储单元。对数组而言,这意味着把加 1 后的地址是下一个元素的地址,而不是下一个字节的地址(见图10.3)。这是为什么必须声明指针所指向对象类型的原因之一。只知道地址不够,因为计算机要知道储存对象需要多少字节(即使指针指向的是标量变量,也要知道变量的类型,否则*pt就无法正确地取回地址上的值)。
现在可以更清楚地定义指向int的指针、指向float的指针,以及指向其他数据对象的指针。
- 指针的值是它所指向对象的地址。地址的表示方式依赖于计算机内部的硬件。许多计算机(包括 PC 和 Macintosh)都是按字节编址,意思是内存中的每个字节都按顺序编号。这里,一个较大对象的地址(如
double类型的变量)通常是该对象第一个字节的地址。 - 在指针前面使用
*运算符可以得到该指针所指向对象的值。 - 指针加 1,指针的值递增它所指向类型的大小(以字节为单位)。
下面的等式体现了 C 语言的灵活性:
1 | dates + 2 == &date[2] // 相同的地址 |
以上关系表明了数组和指针的关系十分密切,可以使用指针标识数组的元素和获得元素的值。从本质上看,同一个对象有两种表示法。实际上,C 语言标准在描述数组表示法时确实借助了指针。也就是说,定义ar[n]的意思是*(ar + n)。可以认为*(ar + n)的意思是“到内存的ar位置,然后移动n个单元,检索储存在那里的值”。
函数、数组和指针
声明数组形参
因为数组名是该数组首元素的地址,作为实际参数的数组名要求形式参数是一个与之匹配的指针。只有在这种情况下,C 才会把int ar[]和int * ar解释成一样。也就是说,ar是指向int的指针。由于函数原型可以省略参数名,所以下面 4 种原型都是等价的:
1 | int sum(int *ar, int n); |
但是,在函数定义中不能省略参数名。下面两种形式的函数定义等价:
1 | int sum(int *ar, int n) |
可以使用以上提到的任意一种函数原型和函数定义。
程序清单 10.10 演示了一个程序,使用sum()函数。该程序打印原始数组的大小和表示该数组的函数形参的大小。
程序清单 10.10 sum_arr1.c 程序
1 | // sum_arr1.c -- 数组元素之和 |
该程序的输出如下:
The size of ar is 8 bytes.
The total number of marbles is 190.
The size of marbles is 40 bytes.
注意,marbles的大小是 40 字节。这没问题,因为marbles内含 10 个int类型的值,每个值占 4 字节,所以整个marbles的大小是 40 字节。但是,ar才 8 字节。这是因为ar并不是数组本身,它是一个指向marbles数组首元素的指针。我们的系统中用 8 字节储存地址,所以指针变量的大小是 8 字节(其他系统中地址的大小可能不是8字节)。简而言之,在程序清单 10.10 中,marbles是一个数组,ar是一个指向marbles数组首元素的指针,利用 C 中数组和指针的特殊关系,可以用数组表示法来表示指针ar。
使用指针形参
上面的sum()函数传递了一个n参数来表示数组的长度,我们还有另外一种方式可以实现,那就是利用两个指针来做遍历,也即是使用指针形参。
程序清单 10.11 sum_arr2.c 程序
1 | /* sum_arr2.c -- 数组元素之和 */ |
指针变量的基本操作
程序清单 10.13 ptr_ops.c 程序
1 | // ptr_ops.c -- 指针操作 |
下面是我们的系统运行该程序后的输出:
pointer value, dereferenced pointer, pointer address:
ptr1 = 0x7fff5fbff8d0, *ptr1 =100, &ptr1 = 0x7fff5fbff8c8adding an int to a pointer:
ptr1 + 4 = 0x7fff5fbff8e0, *(ptr1 + 4) = 500values after ptr1++:
ptr1 = 0x7fff5fbff8d4, *ptr1 =200, &ptr1 = 0x7fff5fbff8c8values after –ptr2:
ptr2 = 0x7fff5fbff8d4, *ptr2 = 200, &ptr2 = 0x7fff5fbff8c0Pointers reset to original values:
ptr1 = 0x7fff5fbff8d0, ptr2 = 0x7fff5fbff8d8subtracting one pointer from another:
ptr2 = 0x7fff5fbff8d8, ptr1 = 0x7fff5fbff8d0, ptr2 - ptr1 = 2subtracting an int from a pointer:
ptr3 = 0x7fff5fbff8e0, ptr3 - 2 = 0x7fff5fbff8d8
赋值:
可以把地址赋给指针。例如,用数组名、带地址运算符(&)的变量名、另一个指针进行赋值。在该例中,把urn数组的首地址赋给了ptr1,该地址的编号恰好是0x7fff5fbff8d0。变量ptr2获得数组urn的第 3 个元素(urn[2])的地址。注意,地址应该和指针类型兼容。也就是说,不能把double类型的地址赋给指向int的指针,至少要避免不明智的类型转换。C99/C11 已经强制不允许这样做。
解引用:
*运算符给出指针指向地址上储存的值。因此,*ptr1的初值是 100,该值储存在编号为0x7fff5fbff8d0的地址上。
取址:
和所有变量一样,指针变量也有自己的地址和值。对指针而言,&运算符给出指针本身的地址。本例中,ptr1储存在内存编号为0x7fff5fbff8c8的地址上,该存储单元储存的内容是0x7fff5fbff8d0,即urn的地址。因此&ptr1是指向ptr1的指针,而ptr1是指向utn[0]的指针。
指针与整数相加:
可以使用+运算符把指针与整数相加,或整数与指针相加。无论哪种情况,整数都会和指针所指向类型的大小(以字节为单位)相乘,然后把结果与初始地址相加。因此ptr1 + 4与&urn[4]等价。如果相加的结果超出了初始指针指向的数组范围,计算结果则是未定义的。除非正好超过数组末尾第一个位置,C 保证该指针有效。
递增指针:
递增指向数组元素的指针可以让该指针移动至数组的下一个元素。因此,ptr1++相当于把ptr1的值加上 4(我们的系统中int为 4 字节),ptr1指向urn[1](见图10.4,该图中使用了简化的地址)。现在ptr1的值是0x7fff5fbff8d4(数组的下一个元素的地址),*ptr的值为 200(即urn[1]的值)。注意,ptr1本身的地址仍是0x7fff5fbff8c8。毕竟,变量不会因为值发生变化就移动位置。
指针减去一个整数:
可以使用-运算符从一个指针中减去一个整数。指针必须是第 1 个运算对象,整数是第 2 个运算对象。该整数将乘以指针指向类型的大小(以字节为单位),然后用初始地址减去乘积。所以ptr3 - 2与&urn[2]等价,因为ptr3指向的是&arn[4]。如果相减的结果超出了初始指针所指向数组的范围,计算结果则是未定义的。除非正好超过数组末尾第一个位置, C 保证该指针有效。
递减指针:
当然,除了递增指针还可以递减指针。在本例中,递减ptr3使其指向数组的第 2 个元素而不是第 3 个元素。前缀或后缀的递增和递减运算符都可以使用。注意,在重置ptr1和ptr2前,它们都指向相同的元素urn[1]。
指针求差:
可以计算两个指针的差值。通常,求差的两个指针分别指向同一个数组的不同元素,通过计算求出两元素之间的距离。差值的单位与数组类型的单位相同。例如,程序清单 10.13 的输出中,ptr2 - ptr1得 2,意思是这两个指针所指向的两个元素相隔两个int,而不是 2 字节。只要两个指针都指向相同的数组(或者其中一个指针指向数组后面的第 1 个地址),C 都能保证相减运算有效。如果指向两个不同数组的指针进行求差运算可能会得出一个值,或者导致运行时错误。
比较:
使用关系运算符可以比较两个指针的值,前提是两个指针都指向相同类型的对象。
解引用未初始化的指针
说到注意事项,一定要牢记一点:千万不要解引用未初始化的指针。例如,考虑下面的例子:
1 | int * pt; // 未初始化的指针 |
为何不行?第 2 行的意思是把5储存在pt指向的位置。但是pt未被初始化,其值是一个随机值,所以不知道 5 将储存在何处。这可能不会出什么错,也可能会擦写数据或代码,或者导致程序崩溃。切记:创建一个指针时,系统只分配了储存指针本身的内存,并未分配储存数据的内存。因此,在使用指针之前,必须先用已分配的地址初始化它。例如,可以用一个现有变量的地址初始化该指针(使用带指针形参的函数时,就属于这种情况)。或者还可以使用第 12 章将介绍的malloc()函数先分配内存。无论如何,使用指针时一定要注意,不要解引用未初始化的指针!
1 | double * pd; // 未初始化的指针 |
假设
1 | int urn[3]; |
下面是一些有效和无效的语句:
| 有效语句 | 无效语句 |
|---|---|
| ptr1++; | urn++; |
| ptr2 = ptr1 + 2; | ptr2 = ptr2 + ptr1; |
| ptr2 = urn + 1; | ptr2 = urn * ptr1; |
指针常量与常量指针
C 语言中的指针是非常基础也是非常复杂难懂的概念,其中配合const使用更会让初学者一头雾水,接下来我们就来看看 C 语言中的常量指针和指针常量。
常量指针
指针指向的对象是常量。
1 | int a = 1; |
因为const修饰的是int,所以pt所指向的内存地址所对应的值是常量不可修改。故,如下写法编译器会报错:
1 | *pt = 10; // Read-only variable is not assignable |
虽然pt指向的内容是不可变的,但是指针本身并没有被const修饰,所以指针本身是可变的,代码如下:
1 | int b = 2; |
指针常量
指针本身是一个常量,所以指针的指向不允许被修改。
1 | int * const pr = &a; |
因为const修饰的是指针pr,所以指针所指向的地址是不可以被修改的,如下代码编译器会报错:
1 | pr = &b; // Cannot assign to variable 'pr' with const-qualified type 'int *const' |
但是变量a并不是常量,所以其值可以被修改,代码如下:
1 | *pr = 100; |
其他写法
如下均表示常量指针,意义相同:
1 | const int * p; |
如下两行代码均表示的是常量指针 p 指向一个 int 常量
1 | const int * const p; |
指针和多维数组
指针和多维数组有什么关系?为什么要了解它们的关系?处理多维数组的函数要用到指针,所以在使用这种函数之前,先要更深入地学习指针。至于第 1 个问题,我们通过几个示例来回答。为简化讨论,我们使用较小的数组。假设有下面的声明:
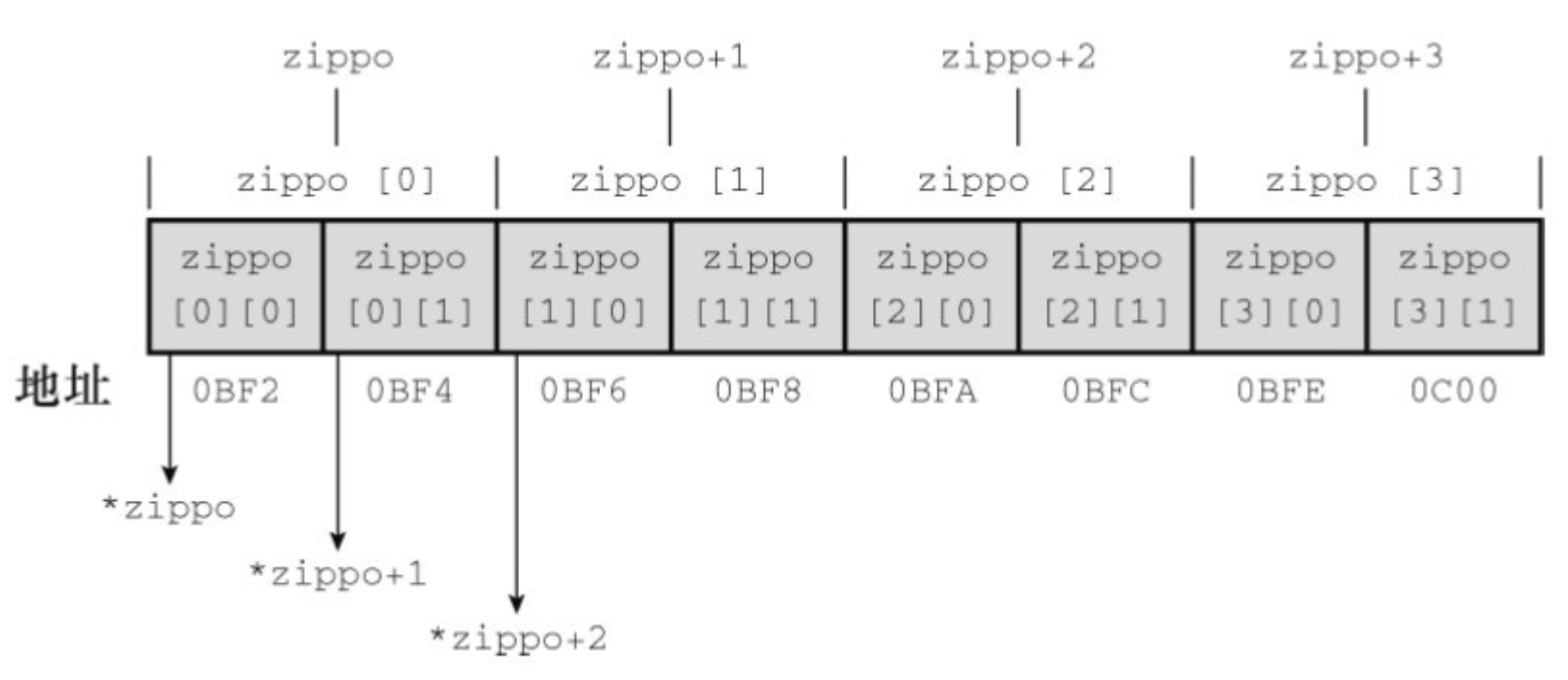
1 | int zippo[4][2]; /* 内含 int 数组的数组 */ |
然后数组名zippo是该数组首元素的地址。在本例中,zippo的首元素是一个内含两个int值的数组,所以zippo是这个内含两个int值的数组的地址。下面,我们从指针的属性进一步分析。
因为zippo是数组首元素的地址,所以zippo的值和&zippo[0]的值相同。而zippo[0]本身是一个内含两个整数的数组,所以zippo[0]的值和它首元素(一个整数)的地址(即&zippo[0][0]的值)相同。简而言之,zippo[0]是一个占用一个int大小对象的地址,而zippo是一个占用两个int大小对象的地址。由于这个整数和内含两个整数的数组都开始于同一个地址,所以zippo和zippo[0]的值相同。
给指针或地址加 1,其值会增加对应类型大小的数值。在这方面,zippo和zippo[0]不同,因为zippo指向的对象占用了两个int大小,而zippo[0]指向的对象只占用一个int大小。因此,zippo + 1和zippo[0] + 1的值不同。
解引用一个指针(在指针前使用*运算符)或在数组名后使用带下标的[]运算符,得到引用对象代表的值。因为zippo[0]是该数组首元素(zippo[0][0])的地址,所以*(zippo[0])表示储存在zippo[0][0]上的值(即一个int类型的值)。与此类似,*zippo代表该数组首元素(zippo[0])的值,但是zippo[0]本身是一个int类型值的地址。该值的地址是&zippo[0][0],所以*zippo就是&zippo[0][0]。对两个表达式应用解引用运算符表明,**zippo与*&zippo[0][0]等价,这相当于zippo[0][0],即一个int类型的值。简而言之,zippo是地址的地址,必须解引用两次才能获得原始值。地址的地址或指针的指针是就是双重间接(double indirection)的例子。
显然,增加数组维数会增加指针的复杂度。现在,大部分初学者都开始意识到指针为什么是 C 语言中最难的部分。认真思考上述内容,看看是否能用所学的知识解释程序清单 10.15 中的程序。该程序显示了一些地址值和数组的内容。
程序清单 10.15 zippo1.c 程序
1 | /* zippo1.c -- zippo的相关信息 */ |
下面是我们的系统运行该程序后的输出:
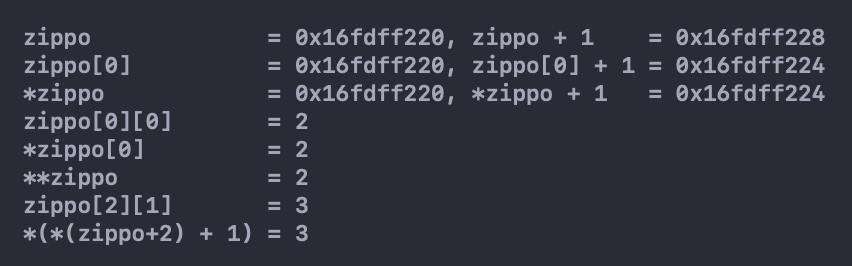
要特别注意,与zippo[2][1]等价的指针表示法是*(*(zippo+2) + 1)。看上去比较复杂,应最好能理解。下面列出了理解该表达式的思路:

下图以另一种视图演示了数组地址、数组内容和指针之间的关系。
指向多维数组的指针
如何声明一个指针变量pz指向一个二维数组(如,zippo)?在编写处理类似zippo这样的二维数组时会用到这样的指针。把指针声明为指向int的类型还不够。因为指向int只能与zippo[0]的类型匹配,说明该指针指向一个int类型的值。但是zippo是它首元素的地址,该元素是一个内含两个int类型值的一维数组。因此,pz必须指向一个内含两个int类型值的数组,而不是指向一个int类型值,其声明如下:
1 | int (* pz)[2]; // pz指向一个内含两个 int 类型值的数组 |
以上代码把pz声明为指向一个数组的指针,该数组内含两个int类型值。为什么要在声明中使用圆括号?因为[]的优先级高于*。考虑下面的声明:
1 | int * pax[2]; // pax 是一个内含两个指针元素的数组,每个元素都指向 int 的指针 |
由于[]优先级高,先与pax结合,所以pax成为一个内含两个元素的数组。然后*表示pax数组内含两个指针。最后,int表示pax数组中的指针都指向int类型的值。因此,这行代码声明了两个指向int的指针。而前面有圆括号的版本,*先与pz结合,因此声明的是一个指向数组(内含两个int类型的值)的指针。程序清单 10.16 演示了如何使用指向二维数组的指针。
程序清单10.16 zippo2.c程序
1 | /* zippo2.c -- 通过指针获取zippo的信息 */ |
下面是该程序的输出:
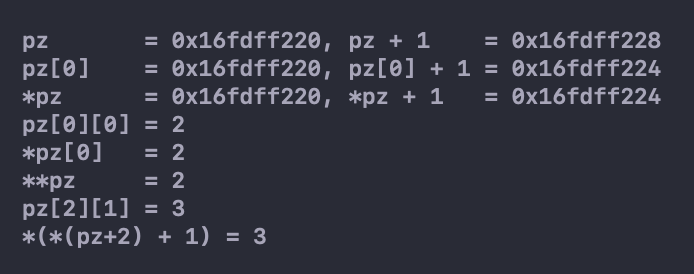
如前所述,虽然pz是一个指针,不是数组名,但是也可以使用 pz[2][1]这样的写法。可以用数组表示法或指针表示法来表示一个数组元素,既可以使用数组名,也可以使用指针名:
1 | zippo[m][n] == *(*(zippo + m) + n) |
多维数组的声明
如果要编写处理二维数组的函数,首先要能正确地理解指针才能写出声明函数的形参。在函数体中,通常使用数组表示法进行相关操作。可以这样声明函数的形参:
1 | void somefunction(int (* pt)[4]); |
另外,如果当且仅当pt是一个函数的形式参数时,可以这样声明:
1 | void somefunction(int pt[][4]); |
注意,第 1 个方括号是空的。空的方括号表明
pt是一个指针。
注意,下面的声明不正确:
1 | int sum2(int ar[][], int rows); // 错误的声明 |
前面介绍过,编译器会把数组表示法转换成指针表示法。例如,编译器会把ar[1]转换成ar+1。编译器对ar+1求值,要知道ar所指向的对象大小。下面的声明:
1 | int sum2(int ar[][4], int rows); // 有效声明 |
表示ar指向一个内含 4 个int类型值的数组(在我们的系统中,ar指向的对象占 16 字节),所以ar+1的意思是“该地址加上 16 字节”。如果第 2 对方括号是空的,编译器就不知道该怎样处理。
也可以在第 1 对方括号中写上大小,如下所示,但是编译器会忽略该值:
1 | int sum2(int ar[3][4], int rows); // 有效声明,但是3将被忽略 |
变长数组
C99 新增了变长数组(variable-length array,VLA),允许使用变量表示数组的维度。如下所示:
1 | int quarters = 4; |
前面提到过,变长数组有一些限制。变长数组必须是自动存储类别,这意味着无论在函数中声明还是作为函数形参声明,都不能使用static或extern存储类别说明符(在之后章节介绍)。而且,不能在声明中初始化它们。最终,C11 把变长数组作为一个可选特性,而不是必须强制实现的特性。
注意 变长数组不能改变大小
长数组中的“变”不是指可以修改已创建数组的大小。一旦创建了变长数组,它的大小则保持不变。这里的“变”指的是:在创建数组时,可以使用变量指定数组的维度。
由于变长数组是 C 语言的新特性,目前完全支持这一特性的编译器不多。下面我们来看一个简单的例子:如何编写一个函数,计算int的二维数组所有元素之和。
首先,要声明一个带二维变长数组参数的函数,如下所示:
1 | int sum2d(int rows, int cols, int ar[rows][cols]); // ar 是一个变长数组(VLA) |
注意前两个形参(rows和cols)用作第 3 个形参二维数组ar的两个维度。因为ar的声明要使用rows和cols,所以在形参列表中必须在声明ar之前先声明这两个形参。因此,下面的原型是错误的:
1 | int sum2d(int ar[rows][cols], int rows, int cols); // 无效的顺序 |
C99/C11 标准规定,可以省略原型中的形参名,但是在这种情况下,必须用星号来代替省略的维度:
1 | int sum2d(int, int, int ar[*][*]); // ar 是一个变长数组(VLA),省略了维度形参名 |
const 和数组大小
是否可以在声明数组时使用
const变量?
2
3
...
double ar[SZ]; // 是否允许?C90 标准不允许(也可能允许)。数组的大小必须是给定的整型常量表达式,可以是整型常量组合,如 20、
sizeof表达式或其他不是const的内容。由于 C 实现可以扩大整型常量表达式的范围,所以可能会允许使用const,但是这种代码可能无法移植。
C99/C11 标准允许在声明变长数组时使用const变量。所以该数组的定义必须是声明在块中的自动存储类别数组。
变长数组还允许动态内存分配,这说明可以在程序运行时指定数组的大小。普通 C 数组都是静态内存分配,即在编译时确定数组的大小。由于数组大小是常量,所以编译器在编译时就知道了。之后章节将详细介绍动态内存分配。
复合字面量
假设给带int类型形参的函数传递一个值,要传递int类型的变量,但是也可以传递int类型常量,如 5。在 C99 标准以前,对于带数组形参的函数,情况不同,可以传递数组,但是没有等价的数组常量。C99 新增了复合字面量(compound literal)。字面量是除符号常量外的常量。例如,5 是int类型字面量, 81.3 是double类型的字面量,'Y'是char类型的字面量,"elephant"是字符串字面量。发布 C99 标准的委员会认为,如果有代表数组和结构内容的复合字面量,在编程时会更方便。
对于数组,复合字面量类似数组初始化列表,前面是用括号括起来的类型名。例如,下面是一个普通的数组声明:
1 | int diva[2] = {10, 20}; |
下面的复合字面量创建了一个和diva数组相同的匿名数组,也有两个int类型的值:
1 | (int [2]){10, 20} // 复合字面量 |
注意,去掉声明中的数组名,留下的int [2]即是复合字面量的类型名。
初始化有数组名的数组时可以省略数组大小,复合字面量也可以省略大小,编译器会自动计算数组当前的元素个数:
1 | (int []){50, 20, 90} // 内含 3 个元素的复合字面量 |
因为复合字面量是匿名的,所以不能先创建然后再使用它,必须在创建的同时使用它。使用指针记录地址就是一种用法。也就是说,可以这样用:
1 | int * pt1; |
注意,该复合字面量的字面常量与上面创建的diva数组的字面常量完全相同。与有数组名的数组类似,复合字面量的类型名也代表首元素的地址,所以可以把它赋给指向int的指针。然后便可使用这个指针。例如,本例中*pt1是 10,pt1[1]是 20。
还可以把复合字面量作为实际参数传递给带有匹配形式参数的函数:
1 | int sum(const int ar[], int n); |
这里,第 1 个实参是内含 6 个int类型值的数组,和数组名类似,这同时也是该数组首元素的地址。这种用法的好处是,把信息传入函数前不必先创建数组,这是复合字面量的典型用法。
可以把这种用法应用于二维数组或多维数组。例如,下面的代码演示了如何创建二维int数组并储存其地址:
1 | int (*pt2)[4]; // 声明一个指向二维数组的指针,该数组内含 2 个数组元素, |
如上所示,该复合字面量的类型是int [2][4],即一个 2×4 的int数组。
程序清单 10.19 把上述例子放进一个完整的程序中。
程序清单 10.19 flc.c 程序
1 | // flc.c -- 有趣的常量 |
记住,复合字面量是提供只临时需要的值的一种手段。复合字面量具有块作用域(以后章节将介绍相关内容),这意味着一旦离开定义复合字面量的块,程序将无法保证该字面量是否存在。也就是说,复合字面量的定义在最内层的花括号中。
总结
数组是一组数据类型相同的元素。数组元素按顺序储存在内存中,通过整数下标(或索引)可以访问各元素。在 C 中,数组首元素的下标是 0,所以对于内含n个元素的数组,其最后一个元素的下标是n-1。作为程序员,要确保使用有效的数组下标,因为编译器和运行的程序都不会检查下标的有效性。
声明一个简单的一维数组形式如下:
1 | type name [ size ]; |
这里,type是数组中每个元素的数据类型,name是数组名,size是数组元素的个数。对于传统的 C 数组,要求size是整型常量表达式。但是 C99/C11 允许使用整型非常量表达式。这种情况下的数组被称为变长数组。
C 把数组名解释为该数组首元素的地址。换言之,数组名与指向该数组首元素的指针等价。概括地说,数组和指针的关系十分密切。如果ar是一个数组,那么表达式ar[i]和*(ar+i)等价。
对于 C 语言而言,不能把整个数组作为参数传递给函数,但是可以传递数组的地址。然后函数可以使用传入的地址操控原始数组。如果函数没有修改原始数组的意图,应在声明函数的形式参数时使用关键字const。在被调函数中可以使用数组表示法或指针表示法,无论用哪种表示法,实际上使用的都是指针变量。
指针加上一个整数或递增指针,指针的值以所指向对象的大小为单位改变。也就是说,如果pd指向一个数组的 8 字节double类型值,那么pd加 1 意味着其值加 8,以便它指向该数组的下一个元素。
二维数组即是数组的数组。例如,下面声明了一个二维数组:
1 | double sales[5][12]; |
该数组名为sales,有 5 个元素(一维数组),每个元素都是一个内含 12 个double类型值的数组。第 1 个一维数组是sales[0],第 2 个一维数组是sales[1],以此类推,每个元素都是内含 12 个double类型值的数组。使用第 2 个下标可以访问这些一维数组中的特定元素。例如,sales[2][5]是slaes[2]的第 6 个元素,而sales[2]是sales的第 3 个元素。
C 语言传递多维数组的传统方法是把数组名(即数组的地址)传递给类型匹配的指针形参。声明这样的指针形参要指定所有的数组维度,除了第 1 个维度。传递的第 1 个维度通常作为第 2 个参数。例如,为了处理前面声明的sales数组,函数原型和函数调用如下:
1 | void display(double ar[][12], int rows); |
变长数组提供第 2 种语法,把数组维度作为参数传递。在这种情况下,对应函数原型和函数调用如下:
1 | void display(int rows, int cols, double ar[rows][cols]); |
虽然上述讨论中使用的是int类型的数组和double类型的数组,其他类型的数组也是如此。然而,字符串有一些特殊的规则,这是由于其末尾的空字符所致。有了这个空字符,不用传递数组的大小,函数通过检测字符串的末尾也知道在何处停止。我们将在以后章节中详细介绍。
参考文献
- C Primer Plus